正規表現を使用し、テキスト内の空行を削除する
正規表現を使用し、テキスト内の空行を削除する方法について紹介します。
正規表現はメモ帳では使用できませんので、今回はSAKURAエディターを使用します。
実行例
1.以下のようなテキストファイルがあるとします。

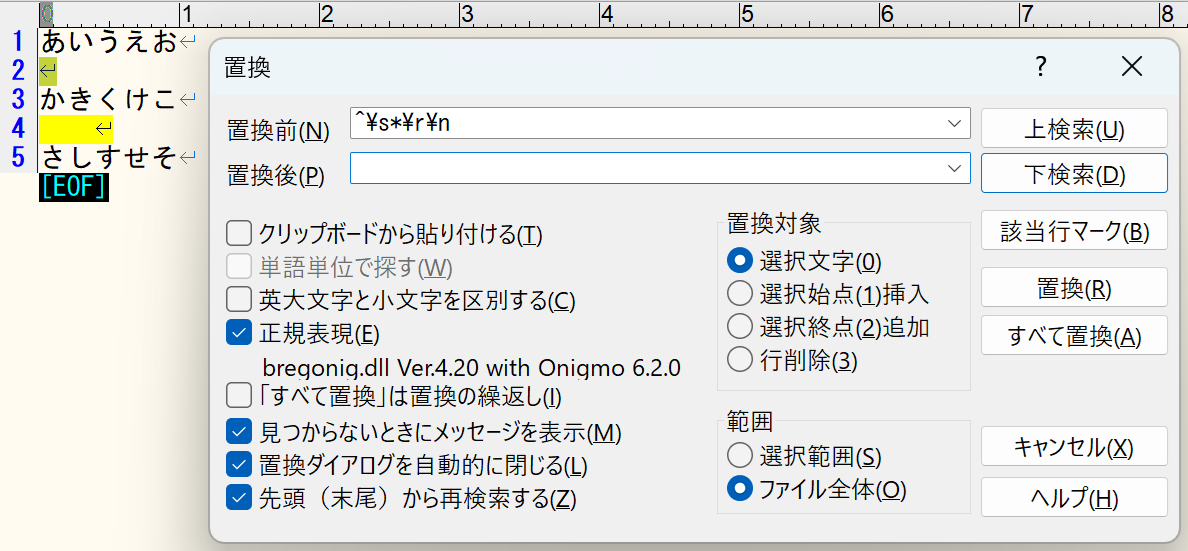
2.置換ダイアログを表示し、「正規表現(E)」をチェックし、「置換前(N)」へ”^\s*\r\n”を入力します。
「下検索(D)」をクリックすると空行箇所がヒットしていることが確認できます。
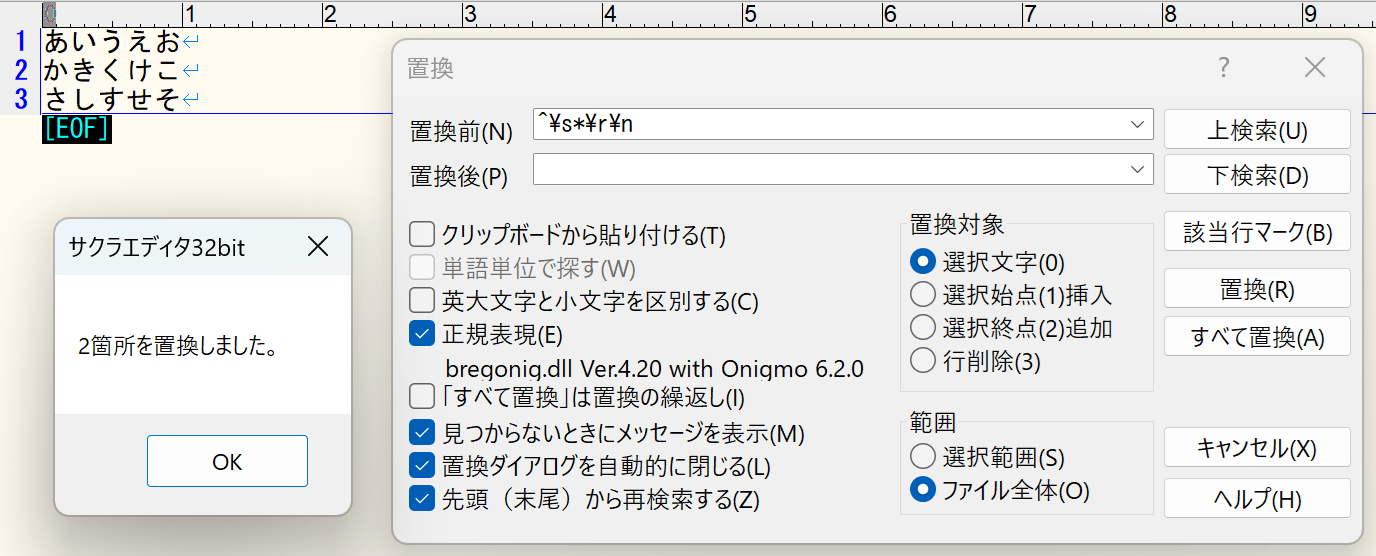
3.「すべて置換(A)」をクリックすると空行がなくなります。
解説
正規表現として以下を指定しています。
^¥s*¥r¥n
「^」(キャレット)は行頭にマッチします。
「¥s」は空白文字にマッチし、スペース・タブ等が該当します。ただし、全角スペースは該当しません。
「*」(アスタリスク)は直前の文字が0回以上繰り返される場合にマッチします。
「¥r¥n」は「¥r」がキャリッジリターン、「¥n」がラインフィードであり、「¥r¥n」はWindowsの改行形式にマッチします。
改行コードはWindowsとLinuxなどOSにより異なりますので、どのOSでもマッチさせる場合は「[¥r|¥n|¥r¥n]+」とします。
ちなみに「$」(ドル)で行末にマッチさせることができますが、「$」は改行コードを含ます、改行コードの手前までとなります。
したがって、上記を組み合わせることで、行頭から空白文字が0回以上繰り返され改行コードで終わる文字列をヒットさせることができ、それを空文字で置換することで改行コードも置換されるため、行が削除されることになります。
以上、正規表現を使用し、テキスト内の空行を削除する方法についての紹介でした。